Raspberry Pi音声認識・合成 クリスマスソング自動再生やってみた DIY 前半
今日はクリスマスイブです!
街はカップルで溢れているのでしょうか。
この時期に家にいると無性にクリスマスソングが聞きたくなります。
でも再生するのが面倒くさいしな・・・。
はうっ!? じゃあ自分で自動再生できる仕組みを作ればいいじゃん!
という事で作ってみました。イメージとしてはこんな感じです。
 古い歌ばかりなのはさておき、コンピューターに話かけると返事をして音楽が再生される仕組みです。
古い歌ばかりなのはさておき、コンピューターに話かけると返事をして音楽が再生される仕組みです。
この前購入したRaspberry Pi2を使ってやってみます。同じような文献はたくさんあるのでサクサク作れました。
目次
準備
準備するもの
- Raspberry Pi Raspberry Pi2 Model B を使用
- マイク SANWA SUPPLY MM-MCUSB16 USBマイクロホン 1600円
- スピーカー 家にあるアナログのPCスピーカー(何でも良いです)
- クリスマス用のCD
以上!これだけで簡単に作れました!
大まかな手順
- スピーカーを使えるようにする
- マイクを使えるようにする、録音できるようにする
- 音声認識できるようにする(Julius)
- 音声合成できるようにする(AquesTalk Pi)
- MP3を再生できるようにする(mpg321)
- プログラムを組んで動かす(Julius + AquesTalk + mpg321)
調べながらやりましたが、なんと総製作時間3~4時間でいけます。便利な世の中になりました。
スピーカーを使えるようにする
これは特に何もしなくてもできました。自分はアナログ端子を使うスピーカーを使いましたが、こんな感じで差すだけで音がなりました。マイクも一緒にUSBに差しておきます。

音の確認はWEBブラウザからYOUTUBEを見て確認しました。ボリュームはデスクトップから設定しました。右上にアイコンがあるので、音を調整するだけです。

マイクを使えるようにする
こちらの文献を参考に設定。これも簡単でした。
まずはUSBポートに接続し認識させる
sudo cat /proc/asound/modules 0 snd_bcm2835 1 snd_usb_audio
1 snd_usb_audioがUSBのマイクデバイスの用なので文献を参考にし、最優先で読み込みがされるようにしました。
設定ファイルを作成します。他の文献だと最初にあるような記載でしたが自分の場合はファイルが最初からなかったです。なので新規に作成しました。
sudo vi /etc/modprobe.d/alsa-base.conf
下記の3行を新規で記載。
options snd slots=snd_usb_audio,snd_bcm2835 options snd_usb_audio index=0 options snd_bcm2835 index=1
記載後一度再起動。すると優先度が0に上がっています。これで大丈夫です。
sudo cat /proc/asound/modules 0 snd_usb_audio 1 snd_bcm2835
マイクのボリューム調整
一旦適当に54に。62が最高とのこと。
amixer sset Mic 54
下記の手順を実施しましたが、何で使用するものなのか不明でした。一応設定
#USBオーディオカード番号 arecord -l #オーディオカード番号を環境変数に指定 export ALSADEV=hw:0
テスト用の録音
マイクが使えているか確認します。
arecord -D plughw:0,0 -d 10 -f cd test.wav
録音が開始されるので、適当に喋ったらCtrl+cで中断。test.wavができるのでwinscp等で操作元のPCにコピーして再生。しっかりと声が録音されていました。
音声認識ができるようにする Juliusの設定
Juliusはオープンソースの音声認識ソフトですが、これはやばいです。オープンソースでここでまで音声認識ができるとは思ってなかったです。素晴らしいの一言です。引き続きこちらの文献を参考にさせて頂きます。
パッケージを3つダウンロード
wget -O julius-4.3.1.tar.gz 'http://sourceforge.jp/frs/redir.php?m=osdn&f=%2Fjulius%2F60273%2Fjulius-4.3.1.tar.gz' wget -O dictation-kit-v4.3.1-linux.tgz 'http://sourceforge.jp/frs/redir.php?m=jaist&f=%2Fjulius%2F60416%2Fdictation-kit-v4.3.1-linux.tgz' wget -O grammar-kit-v4.1.tar.gz 'http://sourceforge.jp/frs/redir.php?m=osdn&f=%2Fjulius%2F51159%2Fgrammar-kit-v4.1.tar.gz'
julius-4.3.1をインストール
tar zxvf julius-4.3.1.tar.gz cd julius-4.3.1/ ./configure make sudo make install
ライブラリを解凍
tar zxvf dictation-kit-v4.3.1-linux.tgz tar zxvf grammar-kit-v4.1.tar.gz
起動時にエラーとならないようにおまじない
sudo sh -c "echo snd-pcm-oss >> /etc/modules"
起動コマンド
julius -C ~/grammar-kit-v4.1/testmic.jconf -charconv EUC-JP UTF-8
これでこんな感じで起動します。
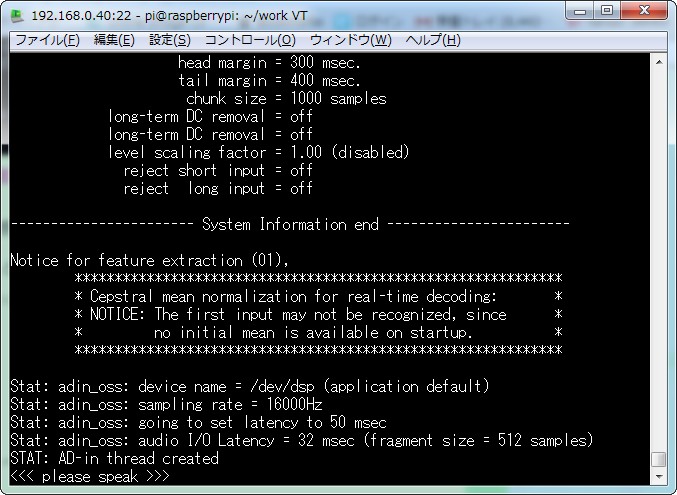
ではやってみましょう。『リンゴを2個ください!』とマイクに喋りかけてみましょう。
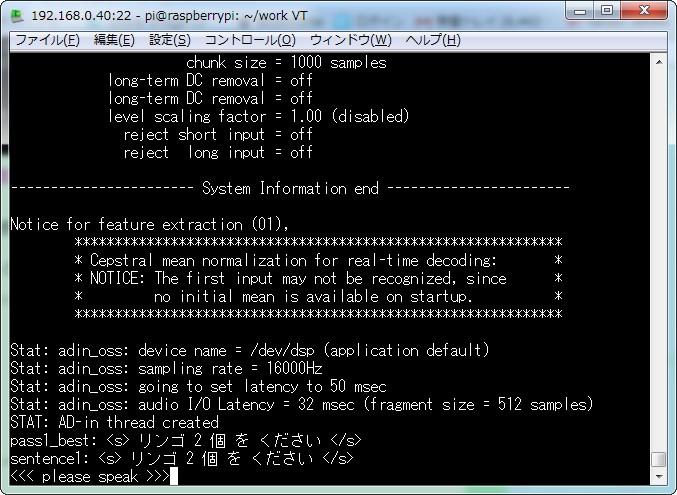
おおおおおお。すげーーーー。一発認識!なんていう精度や。
辞書に登録するだけで簡単に言葉を増やせるそうです。
ライブラリをまとめておく
$mkdir julius-kits $mv grammar-kit-v4.1 julius-kits/ $mv dictation-kit-v4.3.1-linux julius-kits/
辞書の追加
下記のように設定ファイルを作るだけです。
※最後に改行コードだけの行があったりするとエラーになりますので注意。
$vi word.yomi #####↓のような感じで追加### お腹すいた おなかすいた マライヤ まらいや ポールマッカートニー ぽーるまっかーとにー ワム わむ とまれ とまれ #########################
#辞書ファイル作成
iconv -f utf8 -t eucjp ~/word.yomi | ~/julius-4.3.1/gramtools/yomi2voca/yomi2voca.pl > ~/julius-kits/dictation-kit-v4.3.1-linux/word.dic
#設定ファイル作成
vi ~/julius-kits/dictation-kit-v4.3.1-linux/word.jconf ------------word.jconf内での記述----------------------------------------------- -w word.dic #単語辞書ファイル -v model/lang_m/bccwj.60k.htkdic #N-gram、または文法用の単語辞書ファイルを指定する -h model/phone_m/jnas-tri-3k16-gid.binhmm #使用するHMM定義ファイル -hlist model/phone_m/logicalTri #HMMlistファイルを指定する -n 5 #n個の文仮説数が見つかるまで検索を行う -output 1 #見つかったN-best候補のうち、結果として出力する個数 -input mic #マイク使用 -input oss #オープンサウンドシステム使用 -rejectshort 600 #検出された入力が閾値以下なら棄却 -charconv euc-jp utf8 #入出力エンコード指定(内部euc-jp, 出力utf-8) -lv 1000 #入力の振幅レベルの閾値(0~32767) --------------------------------------------------------------------------------
#追加した辞書を使い起動
julius -C ~/julius-kits/dictation-kit-v4.3.1-linux/word.jconf
先ほどと同じ要領で音声を入力。「おなかすいたーーーー」 ・・・
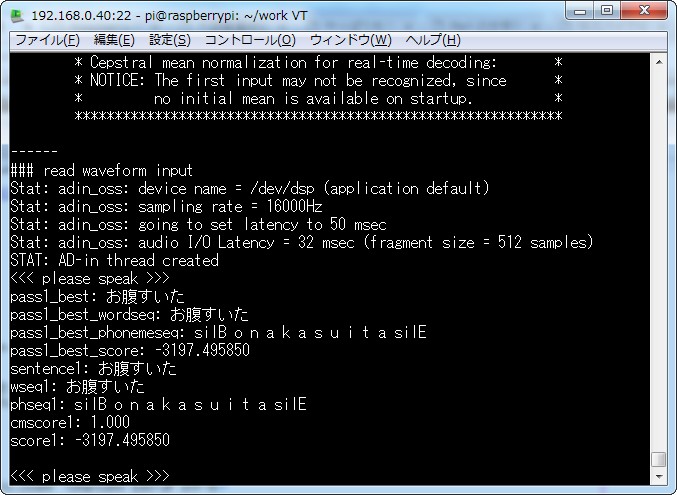 おおおお。あっさり認識されました。これは簡単だ。
おおおお。あっさり認識されました。これは簡単だ。
次回は残りの音声合成とプログラムの動作までを記事にします。
後半へ続く